Packaging ML models using MLflow
Once you have trained a high performing model, you will have to package it so that others can also use your model. Generally, packaging your model is the very first step to deploy any ML model in production. First, we need to understand what it means to package a ML model, and second, why do we need it?
Let me be honest about it, making inference is hard. You cannot feed the input directly to the model, you will first have to process it. This pre-processing can be a simple normalization operation or a complex operation that combines input data with other features stores in different databases. Only once the input is in the right format, it can be fed to the ML model. Furthermore, the prediction (generally tensors) from the model cannot be used directly by end-user. You again will have to apply some post-processing logic to turn these tensors into meaningful information (like class name, probability, time required, etc.). Hence, in MLOps, you never deploy a ML model instead you deploy an end-to-end pipeline.
Yet another thing that makes it even hard, is that ML models fail silently i.e. you won’t get any error even if you have small bug/mistake in you pipeline. But any small change in pre-processing logic will effect your model’s prediction. For example, instead of using imagenet’s mean and std values to normalize an image, if you use (0.5, 0.5, 0.5) as mean and std then you will get very different results. Thus its really important that you always test the complete pipeline and not just the model.
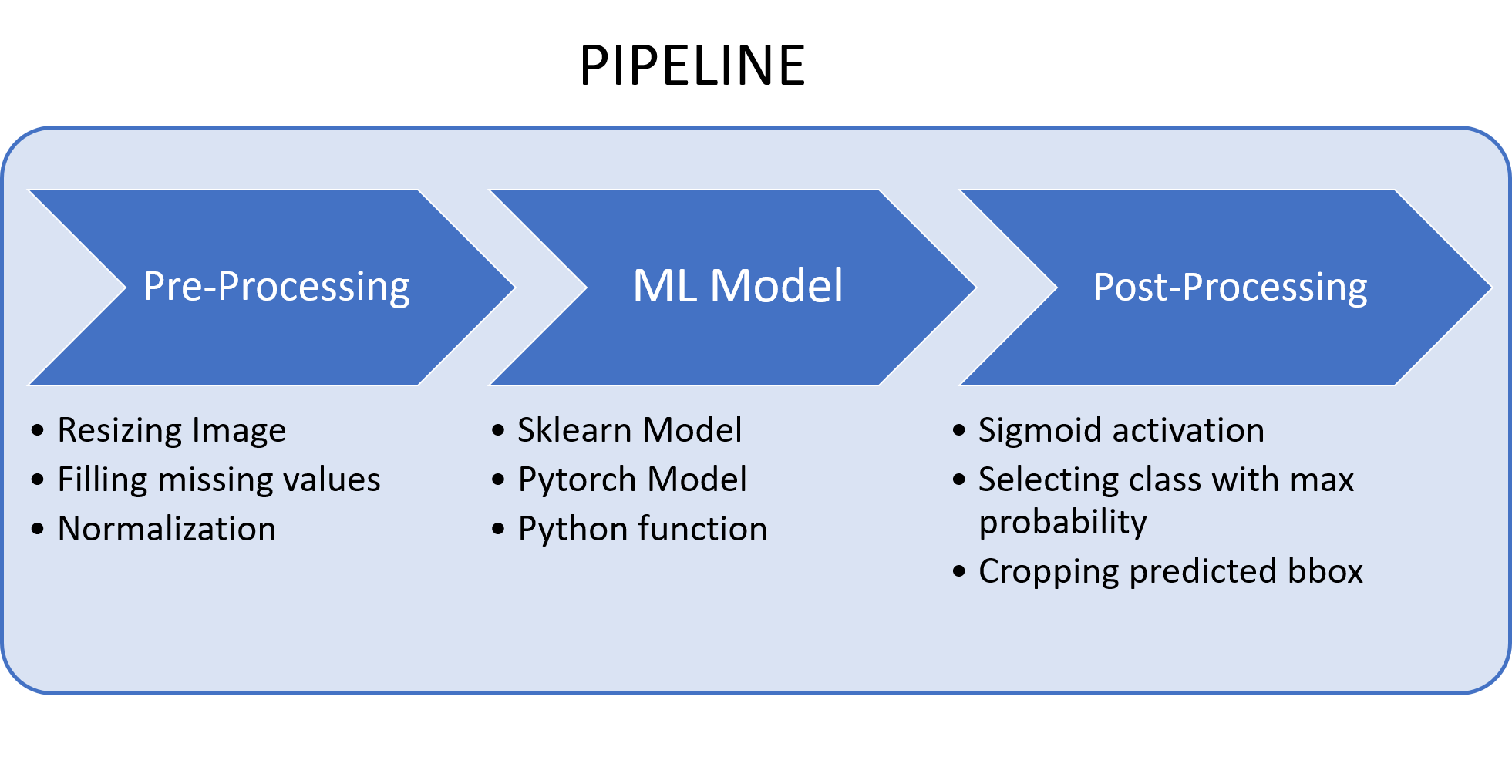
To me, packaging a ML model means wrapping the complete pipeline into an easy to use python package/class. The goal is to abstract away all the complexity from the users, and allow them to interact with the pipeline, through some simple APIs, without worrying about the internals.
Before using MLflow, I use to do exactly the same. Train a model, wrap the pipeline into a python package/class, and finally, write some unit-tests to test the package. But there is one major problems with this brute-force approach : inconsistent APIs. As you start training, and packaging more and more pipelines, this problem will become apparent. Things will get even worst once you start using multiple ML frameworks.
In this tutorial, we will discuss “how we can use MLflow to package our ML models?”. MLFlow makes it super easy (its just a function call). Let me show you . . .
Disclaimer: I will we using pytorch in this blog, but you can use any ML/DL framework. MLflow has built-in support for many frameworks, you can find the complete list of supported frameworks here.
we will start by importing all the required packages. . . .
import mlflow
import torch
from torchvision import models
Here, I will use a ResNet18 model (from torchvision) for the sake of this tutorial, but you can literally use any pytorch model (incase, you are following along).
model = models.resnet18(pretrained=False)
model = model.eval()
lets package our pytorch model using mlflow. We just have to pass the model object, and the path (where want to save it) to mlflow.pytorch.save_model() method.
mlflow.pytorch.save_model(model, 'resnet18_model')
To load you model back into memory, we can again use mlflow. Just pass the model path . . .
## loading pytorch flavour
loaded_model = mlflow.pytorch.load_model('resnet18_model')
easy, right? Lets generate a random tensor and pass it through both the models to make sure that they are the same model
x = torch.rand(4, 3, 224, 224)
x.shape
torch.Size([4, 3, 224, 224])
torch.eq(model(x), loaded_model(x)).all()
tensor(True)
perfect, all the values are equal. You might say, this is same as torch.load_model. What is so special about mlflow? Actually, there are many things that mlflow does under the hood. We will discuss everything that MLflow does in detail but the most obvious benefit is the unified API for saving and loading models (irrespective of the framework).
MLflow Models
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools—for example, real-time serving through a REST API or batch inference on Apache Spark. The format defines a convention that lets you save a model in different “flavors” that can be understood by different downstream tools. Source
Each MLflow Model is a directory containing arbitrary files, together with an MLmodel file in the root of the directory that can define multiple flavors that the model can be viewed in. Flavors are the key concept that makes MLflow Models so powerful : they are a convention that deployment tools can use to understand and load the model. MLflow supports many different ML/DL frameworks, you can find the complete list here. In simple terms, flavor is nothing but a way of abstracting model saving and loading.
Along with the flavor, using which the model was saved, MLflow defines a “standard” flavor that all of its built-in deployment tools support, called “Python function” flavor that describes how to run the model as a Python function. For example, if you save the model using mlflow.pytorch then MLflow will define both pytorch flavor and python function flavor to load the model.
Enough about flavors, its an abstract concept and is very lossly defined. The best way to understand it, is to use MLflow. Lets continue our discussion and see what all files does MLflow generate when packaging a ML model. mlflow.pytorch outputs models as follows:
# Directory written by mlflow.pytorch.save_model(model, 'resnet18_model')
resnet18_model/
├── data
├── model.pth
└── pickle_module_info.txt
├── conda.yaml
├── MLmodel
└── requirements.txt
All of the flavors that a particular model supports are defined in its MLmodel file in YAML format. Here, our MLmodel file describes two flavors:
flavors:
python_function:
data: data
env: conda.yaml
loader_module: mlflow.pytorch
pickle_module_name: mlflow.pytorch.pickle_module
python_version: 3.8.12
pytorch:
model_data: data
pytorch_version: 1.10.1
model_uuid: 2cb018e2588e478a97e626ea187b2c97
utc_time_created: '2022-02-17 17:00:59.055824'
This model can then be used with any tool that supports either the pytorch or python_function model flavor. The ability to deploy you model as a python_function is extremely useful if you plan to use serverless deployment options like AWS Lamda, Azure Functions, Google Cloud functions, etc.
Apart from a flavors field listing the model flavors, the MLmodel YAML format can contain other information like model_uuid and time_created.
Environment recreation
For environment recreation, MLflow automatically logs conda.yaml and requirements.txt files whenever a model is logged. These files can then be used to reinstall dependencies using either conda or pip.
When saving a model, MLflow provides the option to pass in a conda environment as parameter that can contain dependencies used by the model. If no conda environment is provided, a default environment is created based on the flavor of the model. This conda environment is then saved in conda.yaml. You can read more this here.
Input and Output schema
MLflow also allows you to specify extra meta data, such as “What inputs does it expect?” and “What output does it produce?”. This additional metadata about model inputs and outputs can be used by downstream tooling like MLflow model server. And if you plan to use python_function flavor then MLflow will validate each input against input schema. Again, we won’t be discussing this in detail but if you are interested, you can read more about it here.
In summary, when you save your ML model using MLflow, you get the following benefits out-of-the-box:
- An unified API to save and load models, irrespective of the framework
- Simple API to load & use your model as a python function
conda.yamlandrequirements.txtfor recreating python environment- Ability to specify input and output schema
IMO, this is all the information you need to deploy any ML model in production. Additionally, having a standard convention for storing all this information is a huge advantage. Because it will allow others to use your model easily, and will also make it effortless to develop tools for downstream tasks, regardless of framework that was used to train/build the model.
Time to write some code. I told you that MLflow will automatically define a “python function” flavor when you save you model using any standard flavor. So, lets try to load our resnet18_model using mlflow.pyfunc
## load pyfunc flavour
model_pytorch = mlflow.pyfunc.load_model('resnet18_model')
model_pytorch.predict(x.numpy())
array([[-0.3058473 , 0.0832468 , 0.38781884, ..., -1.1486118 ,
-0.7298596 , 0.8924906 ],
[-0.30963922, 0.10418254, 0.39320928, ..., -1.1335343 ,
-0.74505943, 0.8977703 ],
[-0.2785825 , 0.06999737, 0.39136988, ..., -1.1411592 ,
-0.7524246 , 0.8632568 ],
[-0.30011272, 0.08436975, 0.3953184 , ..., -1.1422383 ,
-0.7507808 , 0.8822411 ]], dtype=float32)
You will get the exact same output. Go ahead and verify it yourself. When you load any MLflow model using mlflow.pyfunc, you will have to remember two important things. First, you will have to call the predict method to get model predictions. Another thing to note is that “python_function” models only support pandas dataframe and numpy array as input. Hence, you will have to convert your input tensor to numpy array before passing it to the predict method.
The Resnet18 model, that we saved aboved using mlflow.pytorch.save_model(), works with tensors i.e. tensor in and tensor out. Incase of “python function”, its nd-array in and nd-array out. But in reality, you will not get the data as tensor or nd-array. Plus, you will have to transform the raw input before you can feed it to the model. For example, when you load an image, you will have to resize it, then normalize it and finally convert it into a tensor. Sometimes, this transformation logic can be generic and in other situations, models can have very specific transformations. Hence, repeating myself again, its generally a good practice in MLOps to package the complete pipeline (not just the model).
Saving as pyfunc
MLflow allows you to package any python function as model. This is extremely powerful and flexible at the same time, because it will allow us to package the complete pipeline (both the pre-processing and post-processing logic along with the ML model). Let me show you . . .
import torch
import mlflow
from pathlib import Path
before packaging the actual model, first lets record our environment
from sys import version_info
PYTHON_VERSION = "{major}.{minor}.{micro}".format(major=version_info.major,
minor=version_info.minor,
micro=version_info.micro)
# Create a Conda environment for the new MLflow Model that contains all necessary dependencies.
import cloudpickle
conda_env = {
'channels': ['defaults'],
'dependencies': [
'python={}'.format(PYTHON_VERSION),
'pip',
{
'pip': [
'mlflow',
'torch=={}'.format(torch.__version__),
'cloudpickle=={}'.format(cloudpickle.__version__),
],
},
],
'name': 'mlflow_env'
}
this might look like a lot of code but actually its just a python dictionary. You can always use the same dictionary. Plus, MLflow provides a helper function to get the default dictionary for each flavor, so that you don’t have search for it. For example, you can access the default conda environment for pytorch as follows:
mlflow.pytorch.get_default_conda_env()
{'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': ['python=3.8.12',
'pip',
{'pip': ['mlflow', 'torch==1.10.1', 'cloudpickle==2.0.0']}]}
Now that we have defined our conda environment, lets package the model . . .
First, you must define a Python class which inherits from mlflow.pyfunc.PythonModel, then defining predict() and, optionally define load_context(). load_context() method will be called as soon as you load the this model, and to make predictions you will have to call predict() method because its a python flavor MLflow model. For simplicity, you can think of load_context() as __init__() method and predict() as forward() method in a pytorch model.
# Define the model class
class PytorchWrapper(mlflow.pyfunc.PythonModel):
def load_context(self, context):
import json
from torchvision import models, transforms
self.transforms = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
self.class_names = json.load(open(context.artifacts['imagenet_class_index']))
self.model = models.resnet18(pretrained=True)
return self.model.eval()
def predict(self, context, image):
import torch
from torch.nn import functional as F
with torch.no_grad():
# pre-processing
image = self.transforms(image).float()
image = image.unsqueeze(0)
# prediction
results = self.model(image)
# post-processing
probs = F.softmax(results, dim=-1)
idx = torch.argmax(probs.data).item()
class_name = self.class_names[str(idx)][1]
conf = float(probs[0][idx])
return class_name, conf
Some models also require artifact files like model weights, vocab, config.yaml, etc. To package all the required artifacts along with the model, we will have to create an artifacts dictionary (containing <name, artifact_uri> entries), and pass it while saving the model. Our mlflow.pyfunc.PythonModel can reference these entries as the artifacts property of the context parameter in predict() and load_context() method.
Here, we will need imagenet_class_index.json file to map class names and index. You can download the imagenet_class_index.json file from here and save it in the present working directory.
artifacts = {
"imagenet_class_index" : 'imagenet_class_index.json', # file path in your system
}
we have all the pieces (conda environment, model class, and artifacts dictionary) now. Finally, time to save our model.
# Save the MLflow Model
mlflow.pyfunc.save_model(
path="resnet18_mlflow_pyfunc",
python_model=PytorchWrapper(),
artifacts=artifacts,
conda_env=conda_env
)
Done! we have successfully package a custom ML model along with pre-processing and post-processing logic, and saved it using MLflow. I know this is not the best explanation possible and might look confusing to some. I would recommend reading the above code again, look at a few more examples, and finally, try saving your own custom model. If you are using MLflow for the first time, it will take some time getting use to MLflow.
Lets load our model back and lets try to make some predictions . . .
# Load the model in `python_function` format
loaded_model = mlflow.pyfunc.load_model('resnet18_mlflow_pyfunc')
import requests
from io import BytesIO
from PIL import Image
image_url = 'https://th.bing.com/th/id/OIP.NqzP6hNEcRDD-eHfSRvUFwHaJB?pid=ImgDet&rs=1'
response = requests.get(image_url)
image = Image.open(BytesIO(response.content))
results = loaded_model.predict(image)
results
('Bernese_mountain_dog', 0.7799622416496277)
This was all about packaging ML models using MLflow. Just create a wrapper class, define artifacts dictionary, and another dictionary for conda environment. Then take your model and use it like any other python function.
Note: Make user you install all the required depencies because mlflow.pyfunc does not check for dependencies.
I think the most important take away from this blog should be this
Stop thinking in terms of Models, and start thinking in terms of Pipelines. Always, package and test the complete pipeline.